
What does profile-guided optimization mean?
Some languages have a JIT (Just In Time) compiler available at runtime, that can optimize the executed code depending on current execution patterns. This is, in large part, the cause of the performance of Lua and the JVM. They can start a bit slow, but by accumulating information on actual running code, they make it faster and faster for the current load. PfLua is a great example: the firewall rules are optimized again and again, until the current network traffic is handled as quickly as possible.
When you use other languages, such as C, you usually cannot optimize the application once it is compiled. Except when you use an optimization technique known as Profile-Guided Optimization. From Wikipedia :
Profile-guided optimization (PGO, sometimes pronounced as pogo), also known as profile-directed feedback (PDF), is a compiler optimization technique in computer programming that uses profiling to improve program runtime performance.
It relies on profiling the compiled application, while it runs with the expected, real world load (web traffic, calculations, etc), and feed this profiling information to the compiler. On the next build, the compiler will have more information on which parts of the program are less used, which branches are taken more often, the expected values in a range, etc. Instead of guessing how the program would behave to choose optimizations, the compiler has true information, and can optimize more precisely. There's one issue with the process: you need two compilations and a profiling run to generate the final executable. But it gets easier when you automate it, as we can see in the Firefox build process.
PGO in LLVM
While it has been available in other systems for a long time (Visual Studio 2005, the Intel compiler ICC for Itanium), it appeared recently in LLVM. It has since then been applied successfully to XCode (Objective C, Swift) and LDC, the D compiler.
LLVM has a great feature: it uses an Intermediate Representation code (IR), which is a kind of high level assembly language. It applies its optimizations and machine code generation to that representation. If you make a compiler for a new language, targeting the LLVM IR will give you these features (nearly) for free.
In practice, compiler frontends choose which features they use, so you may not access everything LLVM has to offer. In particular, the Rust compiler, as of now (April 2016), provides a llvm-args option, but that option filters what you can send to LLVM, so we cannot use PGO here.
PGO in Rust
Still, with rustc, you can generate directly the IR, or its binary encoding, named bitcode:
rustc --emit llvm-bc main.rs
# or, with cargo:
cargo rustc -- --emit llvm-bc
The approach I tried here is to take that bitcode, and manually apply LLVM's transformations until I get a compiled executable. This is not really usable for now, especially because I chose an example with very few dependencies. With more dependencies, the compilation and linking will get more complex and unmanageable manually.
LLVM comes with a few commands that you can use to build code manually. The first one is opt, and it applies optimizations and instrumentation on the bitcode file (here, the file target/release/pgo.bc):
opt-3.8 -O2 -pgo-instr-gen -instrprof target/release/pgo.bc -o pgo.bc
The new bitcode file contains code to profile the end application (mainly by counting how often we use each code path). We can now convert that bitcode file to an object file, and link it using clang:
llc-3.8 -O2 -filetype=obj pgo.bc
clang-3.8 -O2 -flto -fprofile-instr-generate pgo.o -L/usr/local/lib/rustlib/x86_64-apple-darwin/lib -lstd-ca1c970e -o pgo
Note: I built my own rustc from source, so your libstd file may not have the same hash. Since Rust (as of April 2016) uses LLVM 3.7, we can use LLVM 3.8's PGO features, since the bitcode format is apparently backward compatible. I use OS X, and Homebrew's LLVM 3.8 has compilation issues, so I needed to build the compiler runtime from source. It's a proof of concept, not production code ;)
We will now run the program we just built, preferably with production data and traffic. It will automatically generate a default.profraw file, containing the profiling information. This file must be transformed to a format that opt will understand with llvm-profdata:
llvm-profdata-3.8 merge -output=pgo.profdata default.profraw
This .profdata file will now be used in the compilation steps:
opt-3.8 -O2 -pgo-instr-use -pgo-test-profile-file=pgo.profdata target/release/pgo.bc -o pgo-opt.bc
llc-3.8 -O2 -filetype=obj pgo-opt.bc
clang-3.8 -O2 -flto -fprofile-instr-use=pgo.profdata pgo-opt.o -L/usr/local/lib/rustlib/x86_64-apple-darwin/lib -lstd-ca1c970e -o pgo-opt
We now have an executable compiled using profiling information. Is it fast?
The benchmarks
The program I tested is a n-body simulation. It was a great test target since libstd is the only dependency, and the load factor depends on a number given as command line argument. Here is a test with time (I know it's not the most precise benchmarking tool, but for a tenth of second precision, it works alright):
$ time ./target/release/pgo 1000000000
-0.169075164
-0.169051540real 1m22.528s
user 1m22.214s
sys 0m0.173s$ time ./pgo-opt 1000000000
-0.169075164
-0.169051540real 1m9.810s
user 1m9.687s
sys 0m0.070s
As it turns out, we gain nearly 15% in running time on this program. Other examples could have less impact, but this is encouraging! So, what happened inside our program?
The generated code
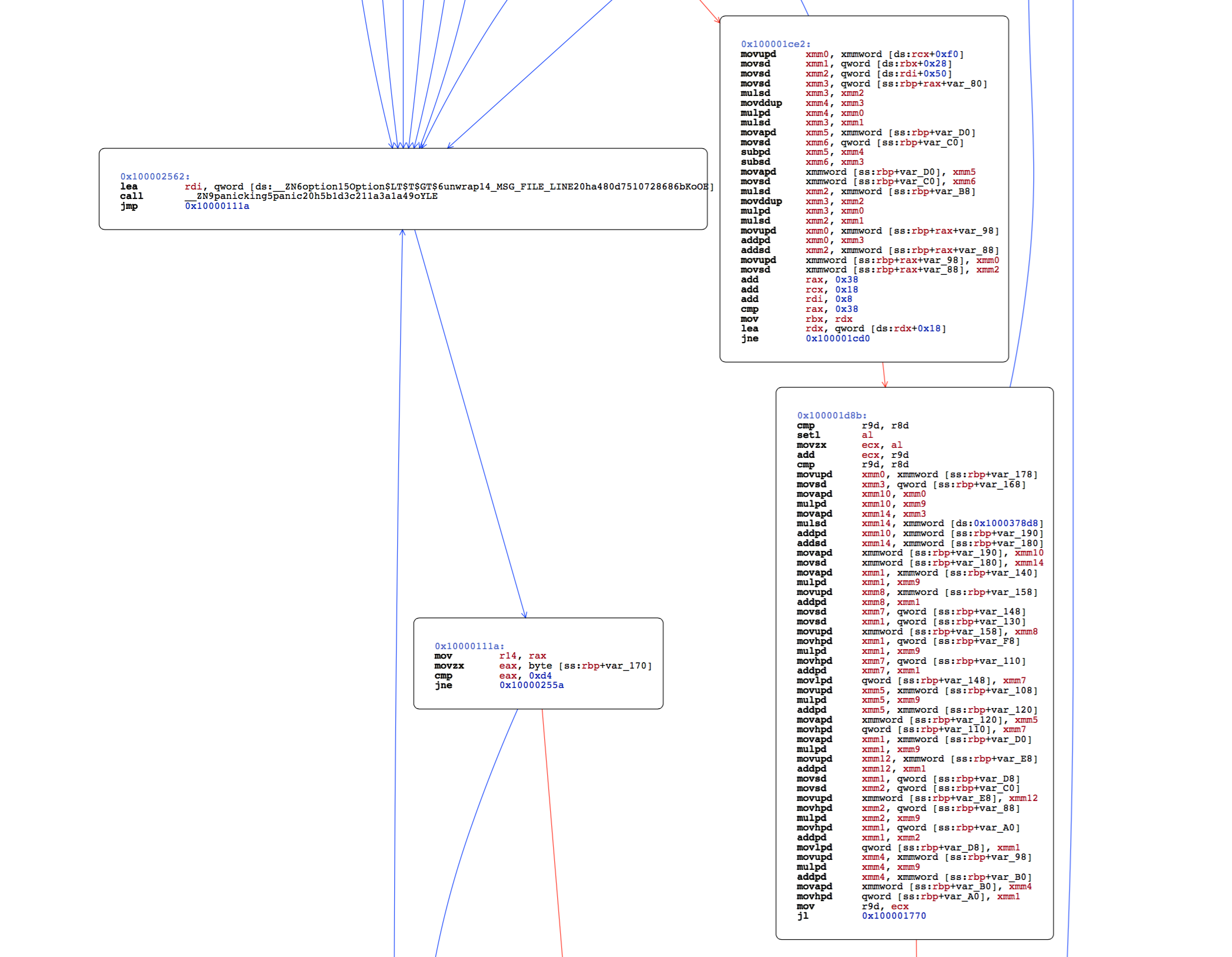
I provide assembly dumps of the normal program, generated with cargo --release, and the one optimized with PGO. Mostly, the code has been reordered, probably to fit better in cache lines. You can also consult PDF files with call graphs: normal, PGO optimized.
The whole code for this article is available here if you want to reproduce the results or tinker with optimizations yourself.
This is a proof of concept, demonstrating that profile guided optimization could work in Rust. It is probably worthy of integration into rustc, but there's a lot of work before it could be usable. Still, there's a github issue where you can weigh in, if you would like this optimization in your applications.