
I’m delighted to announce that nom, the extremely fast Rust parser combinators library, has reached major version 4.
TL;DR: the new nom version is simpler, faster, has a better documentation, and you can find a summary of what changed in the upgrade documentation.
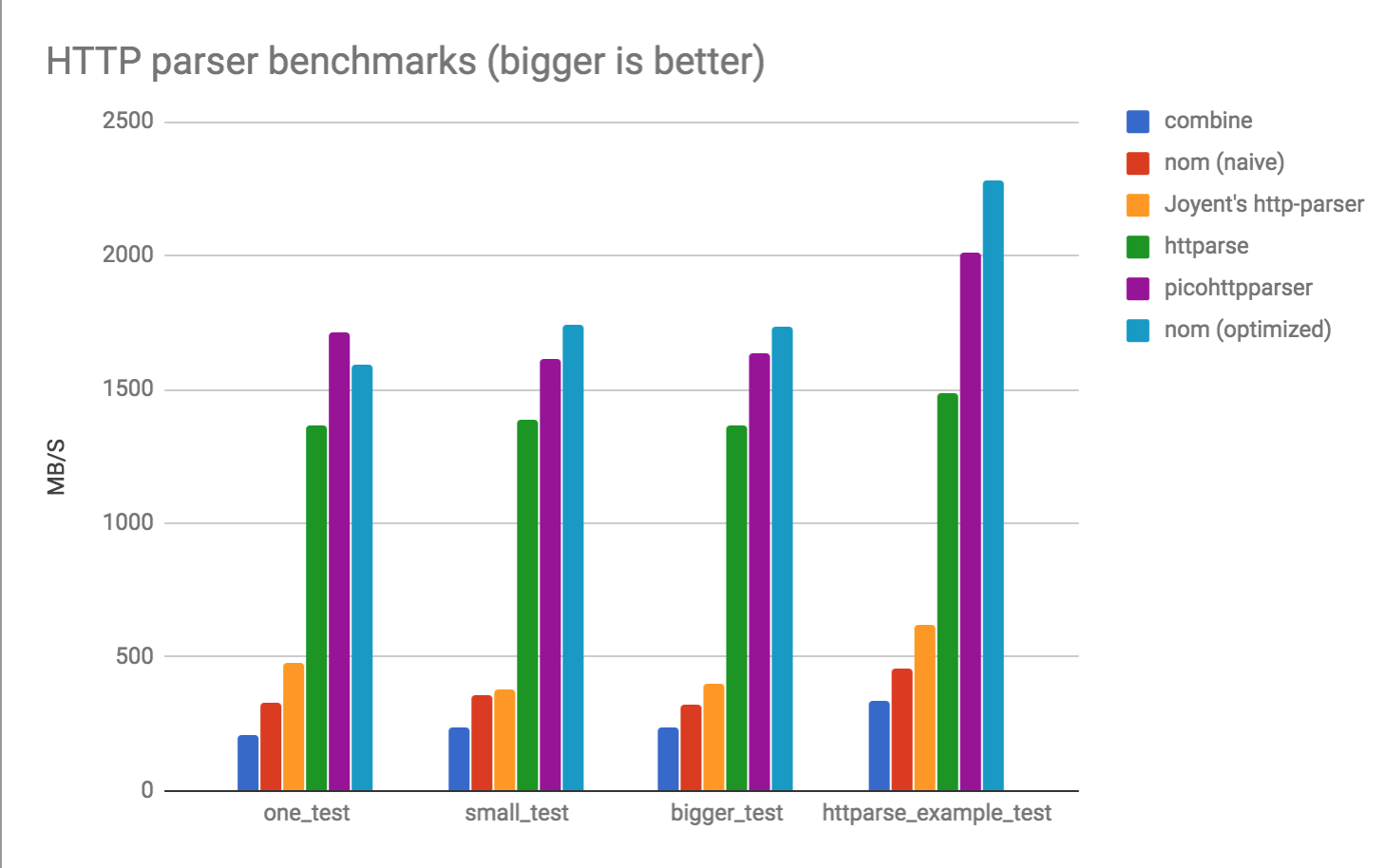
side note: how fast is nom? it can reach 2GB/s when parsing HTTP requests.

Since nom is now a well established, serious project, we got a brand new logo, courtesy of Ange Albertini. The nom monster will happily eat your data byte by byte :)
It took nearly 6 months of development and the library went through nearly 5 entire rewrites. Compare that to previous major releases, which took a month at most to do. But it was worth it! This new release cleans up a lot of old bugs and unintuitive behaviours, simplifies some common patterns, is faster, uses less memory, gives better errors, but the way parsers are written stay the same. It’s like an entirely new engine under the same body work!
Moving from IResult to Result
This was a long standing request. nom used a three-legged enum as return type for the parsers:
// example parser signature
fn parser(input: I) -> IResult<I,O> { ... }
pub enum IResult<I,O,E=u32> {
/// remaining input, result value
Done(I,O),
/// indicates the parser encountered an error. E is a custom error type you can redefine
Error(Err),
/// Incomplete contains a Needed, an enum than can represent a known quantity of input data, or unknown
Incomplete(Needed)
}
pub enum Needed {
/// needs more data, but we do not know how much
Unknown,
/// contains the required total data size
Size(usize)
}
// if the "verbose-errors" feature is not active
pub type Err<E=u32> = ErrorKind;
// if the "verbose-errors" feature is active
pub enum Err<P,E=u32> {
/// An error code, represented by an ErrorKind, which can contain a custom error code represented by E
Code(ErrorKind),
/// An error code, and the next error
Node(ErrorKind, Vec<Err<P,E>>),
/// An error code, and the input position
Position(ErrorKind, P),
/// An error code, the input position and the next error
NodePosition(ErrorKind, P, Vec<Err<P,E>>)
}
That old IResult structure did not transform well to the commonly used Result,
people did not want to see the Incomplete case (when the parser indicates it does
not have enough data to decide) if they do not need it. And the different error types
depending on the verbose-errors feature were confusing and causing errors when nom
appeared multiple times in dependency trees.
So I replaced it with a new, Result based design:
pub type IResult<I, O, E = u32> = Result<(I, O), Err<I, E>>;
pub enum Err<I, E = u32> {
/// There was not enough data
Incomplete(Needed),
/// The parser had an error (recoverable)
Error(Context<I, E>),
/// The parser had an unrecoverable error
Failure(Context<I, E>),
}
pub enum Needed {
/// needs more data, but we do not know how much
Unknown,
/// contains the required additional data size
Size(usize)
}
// if the "verbose-errors" feature is inactive
pub enum Context<I, E = u32> {
Code(I, ErrorKind),
}
// if the "verbose-errors" feature is active
pub enum Context<I, E = u32> {
Code(I, ErrorKind),
List(Vec<(I, ErrorKind)>),
}
Aside from being more compatible with, like, the whole Rust ecosystem, this new design has lots of interesting points:
- the
Contextenum is now extended by theverbose-errorsfeature, so it is the same type - errors always store position information
Incompletehas moved to the error case so you can easily ignore itIResult::Done(remaining, value)has been replaced withOk((remaining, value))so you could easily dolet (remaining, value) = parser(input)?;like you would do with otherResultbased functions- the
Errenum now contains aFailurecase epresenting an unrecoverable error (combinators likealt!will not try another branch)
And we get all of these benefits while keeping the same memory footprint in “simple” errors mode, and reducing it in “verbose” errors mode:
size of IResult |
simple errors | verbose errors |
|---|---|---|
| nom 3 | 40 bytes | 64 bytes |
| nom 4 | 40 bytes | 48 bytes |
And it gets faster! Depending on the format, I have seen improvements between 4% and 40%!
Dealing with Incomplete usage
nom’s parsers are designed to work around streaming issues: if there is not enough data to decide, a
parser will return Incomplete instead of returning a partial value that might be false.
As an example, if you want to parse alphabetic characters then digits, when you get the whole input
abc123;, the parser will return abc for alphabetic characters, and 123 for the digits, and ;
as remaining input.
But if you get that input in chunks, like ab then c123;, the alphabetic characters parser will
return Incomplete, because it does not know if there will be more matching characters afterwards.
If it returned ab directly, the digit parser would fail on the rest of the input, even though the
input had the valid format.
For some users, though, the input will never be partial (everything could be loaded in memory at once),
and the solution in nom 3 and before was to wrap parts of the parsers with the complete!() combinator
that transforms Incomplete in Error.
nom 4 is much stricter about the behaviour with partial data, but provides better tools to deal with it.
Thanks to the new AtEof trait for input types, nom now provides the CompleteByteSlice(&[u8]) and
CompleteStr(str) input types, for which the at_eof() method always returns true.
With these types, no need to put a complete!() combinator everywhere, you can juste apply those types
like this:
named!(parser<&[u8], O>, ... );
// becomes
named!(parser<CompleteByteSlice, O>, ... );
named!(parser<&str, O>, ... );
// becomes
named!(parser<CompleteStr, O>, ... );
And as an example, for a unit test:
assert_eq!(parser("abcd123"), Ok(("123", "abcd"));
// becomes
assert_eq!(parser(CompleteStr("abcd123")), Ok((CompleteStr("123"), CompleteStr("abcd")));
These types allow you to correctly handle cases like text formats for which there might be a last empty line or not, as seen in one of the examples.
If those types feel a bit long to write everywhere in the parsers, it’s possible to alias them like this:
type Input = CompleteByteSlice;
pub fn Input(input:&'a[u8]) -> Input {
CompleteByteSlice(input)
}
Better documentation
Previous documentation was scattered around and hard to navigate, especially when trying to find the exact combinator that would work perfectly for what we want.
So the new README is now more about what can be done instead of an incomplete reference.
The documentation homepage is an introduction to parser
combinators and nom’s design, with some examples to show common combinators
like do_parse.
There’s a brand new “choosing a combinator” doc to help you find what you need, arranged by categories, with example usage and expected results.
And there are new examples for a lot of parser and combinators.
Various fixes
no_std usage is now working correctly. For most of nom’s combinators, you
will not need anything more than core, and a few basic combinators like
many0 or separated_list require alloc.
Some parsers sometimes ended up in the middle of UTF-8 characters, now those streams are handled correctly.
Performance
Here is a comparison of nom’s internal benchmarks, between 3.2.1 and 4.0.0, in default mode:
$ cargo benchcmp 3.2.1.bench 4.0.0.bench
name 3.2.1.bench ns/iter 4.0.0.bench ns/iter diff ns/iter diff %
arithmetic 759 469 -290 -38.21%
ini 998 (109 MB/s) 897 (122 MB/s) -101 -10.12%
ini_key_value 45 (400 MB/s) 47 (382 MB/s) 2 4.44%
ini_keys_values 91 (483 MB/s) 85 (529 MB/s) -6 -6.59%
ini_str 1,399 (77 MB/s) 1,396 (78 MB/s) -3 -0.21%
json_bench 2,149 1,694 -455 -21.17%
http_test 700 659 -41 -5.86%
And here is the difference for verbose errors:
$ cargo benchcmp 3.2.1.bench 4.0.0.bench
name 3.2.1.bench ns/iter 4.0.0.bench ns/iter diff ns/iter diff %
arithmetic 1,731 1,523 -208 -12.02%
ini 1,199 (90 MB/s) 1,061 (103 MB/s) -138 -11.51%
ini_key_value 70 (257 MB/s) 60 (300 MB/s) -10 -14.29%
ini_keys_values 133 (330 MB/s) 111 (405 MB/s) -22 -16.54%
ini_str 1,525 (71 MB/s) 1,621 (67 MB/s) 96 6.30%
json_bench 2,905 2,193 -712 -24.51%
http_test 854 941 87 10.19%
nom 4 is not faster everywhere, ther are still some small regressions that will be fixed soon, but overall we see great improvements.
With nom 4 and some recent work around integrating lookup tables and vectorization in nom parsers, we can get impressive results in HTTP parsing (comparing with combine, Joyent’s http-parser, httparse and picohttpparser):
the future for nom
nom 4 is a huge release, and the new design will probably take some time to settle. There’s probably a lot of low hanging fruit on the performance side, and I look forward to my next obsessive profiling sessions.
Meanwhile, nom will continue to happily munch bytes for you, as one of the fastest, most reliable parsing libraries available.
In the future, I’m interested in supporting more use cases, like zero allocation parsers or Web Assembly usage, and integrating more SIMD work, like what was done for the HTTP parser. The goal is to get nom parsers to secure data access in more and more systems, whatever the language or platform.