
As the main developer of nom, the Rust parser combinators library, I’m usually happy to see other parser libraries appear in Rust. The language’s strengths play well in that space, and writing parsers is a nice way to explore it.
I’m also happy to see them compete in benchmarks with nom, since it keeps me on my toes, and improves performance for everybody. Combine has been an interesting competitor here, showing how far one can go without using macros.
That said, the recent release of pest 2.0, a parsing expression grammar library, is pushing me to be petty :D
That library has been using a benchmark against nom in its readme for a long time. I wrote that benchmark to help in the comparison, but the results were slightly misleading:

The nom benchmark and the “pest (custom AST)” benchmark were
converting the JSON file to Rust types (Vec, HashMap for
objects, booleans, strings and floating point numbers).
While the simple pest parser was validating the file and
generating a list of tokens without converting them.
So, yes, of course it will be faster than nom.
There was further work on the benchmarks, while nom 4 was still in preparation, and pest got interesting results:
The benchmarks were run on a late 2013 Macbook Pro, quad core 2,3 GHz Intel Core i7.
| basic | canada.json | apache_builds.json | data.json | |
|---|---|---|---|---|
| combine | (fails) | 127,775,522 ns/iter (+/- 11,140,676) = 17 MB/s | 3,732,534 ns/iter (+/- 795,836) = 34 MB/s | 241,407 ns/iter (+/- 40,575) = 38 MB/s |
| nom | 1,333 ns/iter (+/- 247) = 57 MB/s | 62,971,567 ns/iter (+/- 6,311,768) = 35 MB/s | 1,209,550 ns/iter (+/- 323,936) = 105 MB/s | 62,008 ns/iter (+/- 11,685) = 149 MB/s |
| pest | 1,405 ns/iter (+/- 238) = 54 MB/s | 27,701,820 ns/iter (+/- 3,961,221) = 81 MB/s | 1,694,463 ns/iter (+/- 338,194) = 75 MB/s | 131,851 ns/iter (+/- 22,667) = 70 MB/s |
I could have left it at that.
But today (October 4th, 2018), the pest website featured a very misleading graph.

Yes, it’s very easy to make nom look bad if you:
- conveniently remove the slowest pest parser
- do not put any link to the benchmark code
- avoid saying how many iterations are done, on which file, etc
- start the horizontal axis at 20ms instead of 0ms, so that nom appears twice slower
this is ridiculous, and deserves all the pettiness I can muster.
The real benchmark
I took the old benchmark reused the canada.json file, added the data.json file from pest’s own JSON benchmark, applied pest’s current way to bench its code in my benchmarks.
After upgrading to nom 4 and pest 2, and fixing some old bugs in the nom parser, I could reproduce the old results (still on a late 2013 Macbook Pro, quad core 2,3 GHz Intel Core i7, yes my laptop is getting old):
- nom:
canada.json: 60,734,229 ns/iter (+/- 17,775,618)data.json: 23,937 ns/iter (+/- 9,992)
- pest:
canada.json: 35,041,472 ns/iter (+/- 5,454,302)data.json: 14,665 ns/iter (+/- 2,041)
Yes, a pest 2.0 parser that does not convert the input to Rust types is indeed faster than a nom 4.0 parser that does convert the input to Rust types.
But what happens if I write a nom 4.0 parser that does not convert its input to Rust types? It’s actually a bit easier if I don’t try to generates floats, bools, etc. It’s not exactly what pest does. Pest stores indexes along with the original slice, while this one will return sub slices for each JSON element. Still, here are the results:
- nom:
canada.json: 60,734,229 ns/iter (+/- 17,775,618)data.json: 23,937 ns/iter (+/- 9,992)
- pest:
canada.json: 35,041,472 ns/iter (+/- 5,454,302)data.json: 14,665 ns/iter (+/- 2,041)
- nom_spans (returning slices instead of converting to Rust types):
canada.json: 20,623,381 ns/iter (+/- 1,952,297)data.json: 10,757 ns/iter (+/- 1,462)
Or, represented as graphs that do not actually mislead us with their axis:
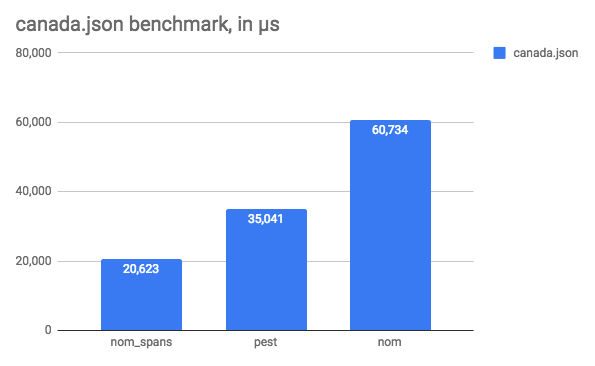
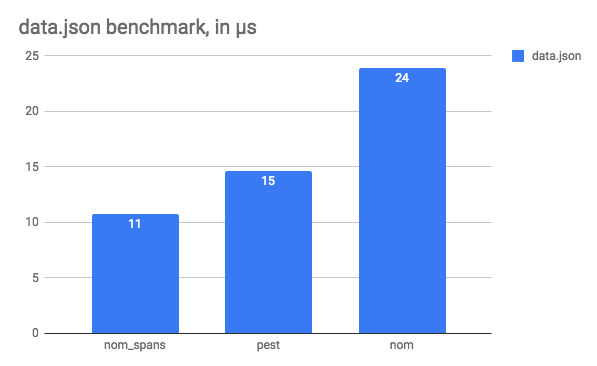
So, here we are, nom is actually still a lot faster than pest. I still find pest’s parser interesting, because the grammar is quite readable, but I tend to prefer parser combinators, because they make it easy to reuse parsers and combinators and allow you to write your own custom elements as you wish.
So, here we are, if you see ways to improve the benchmarks, and in the process make nom or pest faster, please do it :)
